
BBC Radio 2 and Audio Hijack Pro scripts
July 21, 2009 at 6:30 PM by Dr. Drang
Update 9/21/09
While all the logic and thinking behind the scripts in this post is still true, the scripts themselves have been updated. I’ve put everything in a GitHub repository to make it easy to download all at once.
For years I’ve been recording BBC Radio 2’s music shows with Rogue Amoeba’s Audio Hijack Pro. I import the recordings into iTunes and transfer them to my iPod or iPhone to listen to while biking, driving, or working. More recently, I’ve been copying the tracklists from some shows’ web pages and adding that to the iTunes Lyrics field so I can quickly look up the song I’m listening to. And, of course, I’ve been working on ways to automate the process.
In the past couple of months, Radio 2 revamped its web site; the web pages for all the shows now have a uniform layout, with links to the Listen Again streams and lists of the songs played. This makes the site much easier to use, and it also gives me an opportunity to automate my recordings. This post describes my recording setup and the various scripts I use to do the recording and extract the song lists.
I’ve described this sort of thing before, but that was before the Radio 2 web redesign. This post supersedes that earlier work.
Radio 2 web layout
Before the redesign, each show on Radio 2 had its own web page, or set of web pages. Typically, these pages would have a link to the Listen Again stream of the most recent episode. They might also include a list of the songs played in that most recent episode. The nice thing about this arrangement, for the purposes of automation, was that each show had a single URL for its Listen Again stream and a single URL for its general information page. The bad thing about the arrangement was that each show’s information page was organized in its own way; if you wanted to screen scrape the song list, you had to write a different scraping program for each show.
Now things are different. Instead of a page for each show, there’s a page for each episode of each show. The list of songs played on that episode are contained within a particular <div>. The title and artist of each song is set inside <span> tags with classes that identify the type of information.
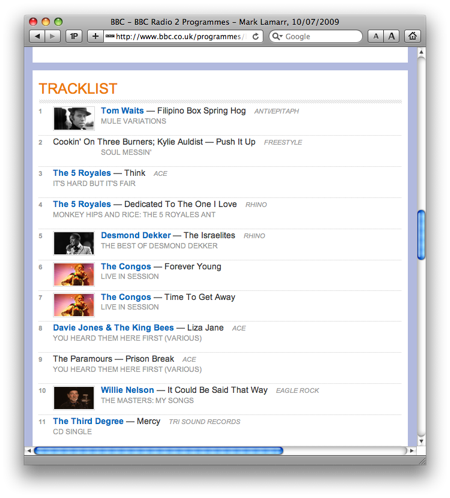
If the episode was aired within the past week, its page will also have a link to the streaming audio of that episode. Because this layout is the same for every show, we can write a single script to scrape the song list from any show. The only problem for automating this process is finding the URL for episode you want to record.
The key to finding episode URLs is the daily schedule page. Its URL is based on the date—today’s is http://www.bbc.co.uk/radio2/programmes/schedules/2009/07/21. The daily schedule page has links to every program broadcast that day, and its layout is logical and easy to scrape. Here, for example, is the schedule for last Saturday:
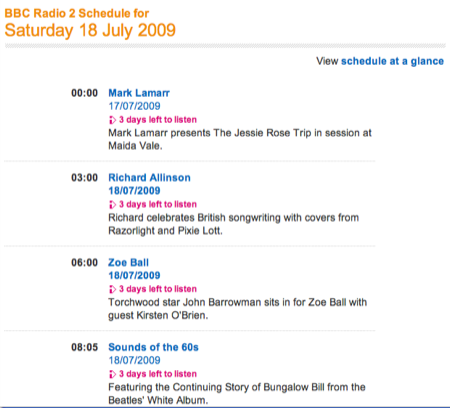
Each episode has a unique eight-character code associated with it. The code is part of the URL for the stream and part of the URL for the program page with the playlist. We’ll use both of these URLs to do our recording and post-processing.
Strategy
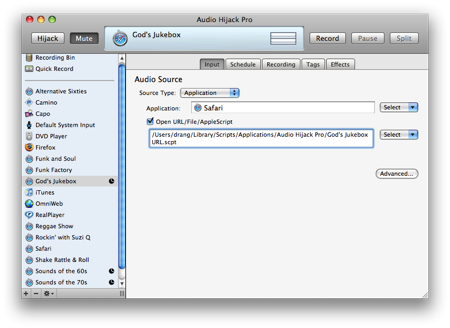
Audio Hijack Pro can be scheduled to record streams at our convenience—in the middle of the night, for example. To do that, it needs the URL of the stream we want to record. If this is a static URL, we just give it that; but if it changes from day to day or week to week—as the Radio 2 streams do—we need to write an AppleScript that will deliver the current URL to Audio Hijack Pro. The name and location of that script is entered on Audio Hijack Pro’s Input tab.
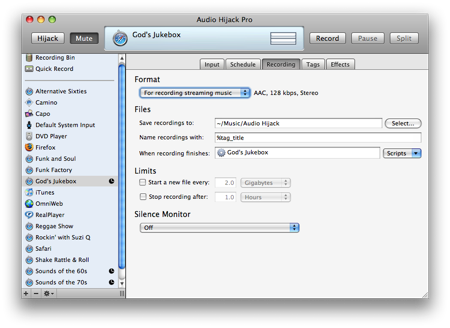
Audio Hijack Pro can also run scripts to post-process a track after it’s been recorded. We’ll use this capability to:
- extract the list of songs from the program page and turn it into plain text
- import the recorded show into iTunes
- set the lyrics of the show to the song list
- set the “Remember playback position” option
- set the “Skip when shuffling” option
The name of the post-processing script is entered on Audio Hijack Pro’s Recording tab.
Unfortunately, the URL-finding script and the post-processing script have to be written in AppleScript because that’s the only kind of script Audio Hijack Pro understands. Since only the brave or the stupid would attempt serious HTML parsing and text processing in AppleScript, we’ll do the heavy lifting in Python, and then write AppleScripts that use do shell script to run the Python code.
Since both the URL-finding script and the post-processing script need the program’s eight-character code, we’ll write a Python module that contains all the programming needed to get that code, and we’ll import that module into both of the scripts.
HTML parsing will be done by the Beautiful Soup library. This is not part of the standard Python library, so we’ll have to download and install it using the instructions that come with the download.
Module
The Radio 2 module consists of three parts:
- a dictionary with information about the shows I’m interested in;
- a function that returns the URL for the schedule page with the most recent episode of a given show; and
- a function that returns the eight-character code for that episode.
Here’s the module:
1: import datetime
2: import urllib
3: import BeautifulSoup
4: import re
5:
6: # The particulars for the shows we're interested in.
7: showinfo = {'jukebox': (5, 'Mark Lamarr'),
8: '70s': (6, re.compile(r'Sounds of the 70s')),
9: '60s': (5, re.compile(r'Sounds of the 60s')),
10: 'soul': (2, 'Trevor Nelson')}
11:
12:
13: def recentScheduleURL(showday, day=datetime.date.today()):
14: 'Return the schedule URL for the most recent showday (0=Mon, 6=Sun) on or before day.'
15:
16: backup = datetime.timedelta((day.weekday() - showday) % 7)
17: programDay = day - backup
18: return 'http://www.bbc.co.uk/radio2/programmes/schedules/%d/%02d/%02d' % (programDay.year, programDay.month, programDay.day)
19:
20:
21: def programCode(show):
22: 'Return the code of the program page for showname on the most recent showday.'
23: try:
24: schedHTML = urllib.urlopen(recentScheduleURL(showinfo[show][0])).read()
25: schedSoup = BeautifulSoup.BeautifulSoup(schedHTML)
26: return schedSoup.find(name='span', text=showinfo[show][1]).parent.parent['href'].split('/')[-1]
27: except KeyError:
28: return None
The recentSchedule function makes use of what we know about the form of the URL for the daily schedule page. If we call recentScheduleURL(5) today, it will return
http://www.bbc.co.uk/radio2/programmes/schedules/2009/07/18
which is the schedule for last Saturday, the most recent Saturday (5) on or before today.
The programCode function opens the URL returned by recentScheduleURL and parses the HTML to find the link to the show of interest. It then pulls the eight-character episode code out of that link.
The programCode function uses the show day and name (which can be either a string or a regular expression), which are kept in the showinfo dictionary. I have the information for only four shows in that dictionary, but it can easily be extended.
The name of the module is “radio.py,” and it should be put in the /Library/Python/2.5/site-packages directory.
(If you’re on Linux or Windows, and want to modify my scripts to work on your system, you’ll have to put “radio.py” in the appropriate site-packages directory on your hard drive. You can find it by launching an interactive session of Python and executing
>>> import sys
>>> for p in sys.path:
... print p
...
This will print out the full path name of each directory Python searches for modules, one per line. The one that ends with site-packages is the one you want.)
Script for getting the streaming URL
Now that we have the “radio2.py” module, writing a script that returns the URL of the audio stream of the most recent episode of a given show is easy. Here’s the Python program, called “radio2-stream” and kept in my ~/bin directory.
1: #!/usr/bin/python
2:
3: import radio2
4: import sys
5:
6: # Set the info from the command line argument.
7: show = sys.argv[1]
8:
9: print 'http://bbc.co.uk/iplayer/console/' + radio2.programCode(show)
It takes as its sole argument a string that identifies the show of interest. The strings it recognizes are the keys of the showinfo dictionary defined in “radio.py.”
- “jukebox” for Mark Lamarr’s God’s Jukebox program
- “70s” for Johnny Walker’s Sounds of the 70s
- “60s” for Brian matthew’s Sounds of the 60s
- “soul” for Trevor Nelson’s eponymous soul/funk show
If I execute
radio2-stream jukebox
today, I get
http://bbc.co.uk/iplayer/console/b00lqcgw
With this Python script in place, we can write the AppleScript wrapper that AHP will run to get the streaming URL for God’s Jukebox.
return do shell script "~/bin/radio2-stream jukebox"
This is the entire “God’s Jukebox URL” script shown in the Audio Hijack Pro Input tab above. It can be stored anywhere; I keep it in the ~/Library/Scripts/Applications/Audio Hijack Pro folder.
Script for getting the playlist
The Python script for extracting the playlist from the episode page is called “radio2-tracklist” and is kept in my ~/bin directory.
1: #!/usr/bin/python
2:
3: import radio2
4: import sys
5: from BeautifulSoup import BeautifulSoup, BeautifulStoneSoup
6: from urllib import urlopen
7:
8: def trackList(show):
9: 'Return text with the track and artist names for each song played.'
10:
11: # Get all the track info
12: progURL = 'http://bbc.co.uk/programmes/' + radio2.programCode(show)
13: progHTML = urlopen(progURL).read()
14: progSoup = BeautifulSoup(progHTML)
15: tracklist = progSoup.findAll('div', 'summary')
16:
17: # Create a list of songs with title and artist.
18: songinfo = []
19: for t in tracklist:
20: track = t.find('span', 'track').string
21: artist = t.find('span', 'artist').string
22: songinfo.append('%s\nby %s' % (track, artist))
23:
24: # Generate a plain text list of the song information.
25: songs = '\n\n'.join(songinfo)
26: songs = BeautifulStoneSoup(songs, convertEntities=BeautifulStoneSoup.HTML_ENTITIES)
27:
28: # Get the date of the show.
29: bdate = progSoup.find('div', 'date').span.string
30:
31: return '%s\n\n%s' % (bdate, songs)
32:
33: # Set the info from the command line argument.
34: show = sys.argv[1]
35:
36: print trackList(show).encode('utf-8')
Like “radio2-stream,” it takes as its single argument the string identifying the show of interest. It uses the programCode function of “radio.py” to construct the URL of the episode page and BeautifulSoup to parse the page’s HTML and get the title and artist for each track in the playlist. It then spits this information out in the form
Song Title
by Artist
with a blank line between each track. The episode date is put at the beginning of the output.
So if we execute
radio2-tracklist jukebox
today, we’ll get
Sat 18 Jul 2009
Backlash
by Freddie Hubbard
Worries In The Dance
by Frankie Paul
Ran Kan Kan
by Tito Puente
and so on.
Update 9/3/09
A week or so ago, Radio 2 changed its internal nomenclature. The div with the tracklist, which used to have an id of type-musicsegment, now has an id of summary. That change is now reflected in Line 15 of radio2-tracklist.
Script for importing into iTunes
With “radio2-tracklist” in place, we can write the AppleScript that AHP will run after the show is recorded. Because there’s no way to pass arguments to an AHP Recording Script, we’ll have to write a separate one for each show. For God’s Jukebox, the script looks like this:
1: (* Audio Hijack Script *** (C) Copyright 2003-2007, Rogue Amoeba Software, LLC
2: "set shufflable" and "set bookmarkable" lines added on 20070725
3: "add to Radio shows" line added on 20080904
4: song list processing updated on 20090715 *)
5:
6: on process(theArgs)
7:
8: --Get the list of songs from the BBC Radio 2 page
9: try
10: set songlist to do shell script "~/bin/radio2-tracklist jukebox"
11: on error
12: set songlist to "Couldn't retrieve song list"
13: end try
14:
15:
16: --Coerce args to be a list
17: if class of theArgs is not list then
18: set theArgs to {theArgs}
19: end if
20:
21: --Into iTunes ye files shall go
22: tell application "iTunes"
23: set theFile to item 1 of theArgs
24: set aTrack to (add theFile)
25: delay 60
26: set bookmarkable of aTrack to true
27: set shufflable of aTrack to false
28:
29: add (get location of aTrack) to playlist "Radio shows"
30: set lyrics of aTrack to songlist
31:
32: end tell
33:
34: end process
This is the “God’s Jukebox” script shown in the Audio Hijack Pro Recording tab screenshot above. It has to be kept in the ~/Library/Application Support/Audio Hijack Pro/Recording Scripts folder in order to be accessible through the popup menu.
As the comments at the top of the script indicate, this is just an extended version of the sample script Rogue Amoeba provides for importing AHP recordings into iTunes. The additions are
- Lines 8–13, which execute “radio2-tracklist” and put the output into the
songlistvariable. - Line 25, which is an ad hoc delay that gives iTunes a chance to import the track before changing its settings.
- Line 26, which is equivalent to setting the “Remember playback position” option.
- Line 27, which is equivalent to setting the “Skip when shuffling” option.
- Line 29, which puts the new track into the “Radio shows” playlist.
- Line 30, which sets the lyrics of the track to the contents of the
songlistvariable.
If you know your way around iTunes, you may be wondering why we’re putting the song list in the lyrics field instead of the “long description” field. The long description field does seem like the perfect place for this information, but unfortunately, the iPhone doesn’t display it. So we have to use the lyrics field instead.
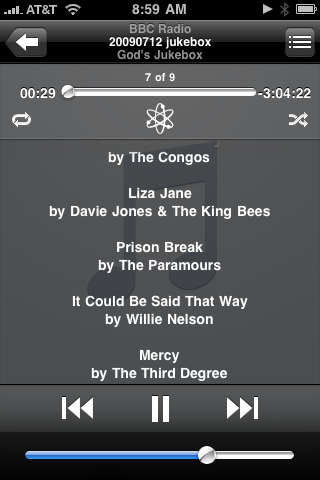
And so…
This system—a commercial program that calls AppleScripts that call Python scripts that call a Python module—is more complex than most of the programming I show on this blog, but it provides a seamless experience once it’s set up. The programs get recorded, popped into iTunes with song lists, and put into an iTunes playlist that’s synced to my iPod/iPhone the next time it’s docked. It took a some effort to get it working, but it’s been smooth sailing ever since.