
Radio show song lists
January 12, 2009 at 11:23 PM by Dr. Drang
Update 7/24/09
This post has been superseded by this one. The scripts have been made more general and have been updated to work with Radio 2’s new web layout.
I’ve been using AudioHijack Pro to record the streams of Mark Lamarr’s shows on BBC Radio 2 for a few years now, and I’ve often found myself going back through a show to get a song title and artist name. Last week I decided that this was silly. The song lists for his shows are posted every week; I should just screen scrape those lists, transform them into plain text, and save them as the lyrics of the recording. It turned out to be pretty simple, and because AudioHijack Pro allows you to schedule scripts to run when a recording is finished, the song lists are added automatically.
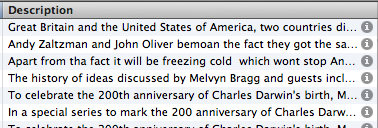
Let’s start by looking at an excerpt of the song list page for last week’s Alternative Sixties show:
<div class="content-rm"><h5>MUSIC PLAYED<br />
This Week | <a href="/radio2/shows/lamarr/musiclast.shtml" >Last Week</a><br />
<br />
</h5><p><strong>The Alternative 60s<br />
<br />
Thursday, 8 January 2009<br />
<br />
</strong>Title: 'WHERE YOU GONNA GO?'<br />
Artist: UNRELATED SEGMENTS<br />
Album: GARAGE BEAT VOLUME 7 - THAT'S HOW IT WI<br />
Label: WHITE LABEL<br />
<br />
Title: 'AND NOW YOU WANT MY SYMPATHY'<br />
Artist: THE OUTSIDERS<br />
Album: VINYL SINGLE<br />
Label: CAPITOL RECORDS<br />
<br />
Title: 'COME ON'<br />
Artist: FREDDIE KING<br />
Album: BLUES GUITAR HERO<br />
Label: ACE<br />
<br />
Title: 'CLUB NITTY GRITTY'<br />
Artist: CHUCK BERRY<br />
Album: CHUCK BERRY'S GOLDEN HITS<br />
Label: MERCURY<br />
<br />
.
.
.
Title: 'SEARCHING IN THE WILDERNESS'<br />
Artist: ALLAN POUND'S GET RICH<br />
Album: MAXIMUM FREAKBEAT<br />
Label: PAST & PRESENT<br />
<br />
</p><ul></ul><div style="clear: both;"></div></div>
I should have warned the sensitive web designers among you to avert your eyes. I’m sure the barrage of <br /> tags are making you ill. Fortunately for me, though, this poorly written HTML is a breeze to transform into plain text. The script that does it is a short Python program that uses the Beautiful Soup parsing and extraction library.
1: #!/usr/bin/python
2:
3: from BeautifulSoup import BeautifulSoup, BeautifulStoneSoup
4: import sys
5:
6: usage = '''
7: This is a filter to create a plain text list from the song lists of
8: Mark Lamarr's BBC Radio 2 shows. The script is intended to be called
9: from an AppleScript that is run by AudioHijack Pro after AHP records
10: the show. The filter expects the HTML from the BBC's show page (which
11: contains the song list) to be passed in through STDIN.
12: '''
13:
14: # Get the BBC's HTML through STDIN.
15: html = sys.stdin.read()
16:
17: # Parse the HTML and get just the <p> with the song list.
18: soup = BeautifulSoup(html)
19: songlist = soup('div', 'content-rm')[0]('p')[0]
20:
21: # Now turn it into plain text.
22: songlist = ''.join(songlist.findAll(text=True)).strip()
23:
24: # Convert the HTML entities to characters.
25: songlist = BeautifulStoneSoup(songlist, convertEntities=BeautifulStoneSoup.HTML_ENTITIES)
26:
27: print songlist
As mentioned in the usage string, the script is written as a filter. It expects the HTML of the songlist web page to be fed to it via STDIN (Line 15) and it spits out the plain text extract via STDOUT (Line 27). The heavy lifting is done by Beautiful Soup in Lines 18 and 19. Line 18 parses the HTML, and Line 19 extracts the single paragraph inside the single <div> with a class of content-rm. Line 22 then grabs and concatenates the text of that paragraph, leaving behind all those <br />s, and strips any trailing whitespace. The last bit of work is done in Line 25, which turns any HTML entities (things like &) into single characters.
With the filter is done, I needed to write a script that AudioHijack Pro can run automatically when the show is done recording. The script had to
- Add the newly-recorded audio file to iTunes.
- Set the track’s bookmarkable property to true, so I can stop the show and pick back up where I left off.
- Set the track’s shufflable property to false, so my iPod/iPhone won’t play it when I’m playing songs in shuffle mode.
- Put the track into the “Radio shows” playlist in iTunes.
- Grab the song list from the web, run it through the filter above, and put the results into the track’s lyrics field.
(It would make more sense to put the song list in the track’s “long description” field, but the long description field can only be viewed for podcasts—it’s what’s in the window that comes up when you click on the circled “i” at the end of the podcast’s short description in iTunes—and can’t be viewed at all on the iPhone. So the lyrics field was the only practical option.)
AudioHijack Pro needs this script to be written in AppleScript, a language whose “English-like” syntax sets my teeth on edge. Luckily, the fine folks at Rogue Amoeba provided an example script that did Step 1. I had already modified it to do Steps 2, 3, and 4, so I just needed to add the filtering stuff in Step 5. Here’s what I came up with.
1: (* Audio Hijack Script *** (C) Copyright 2003-2007, Rogue Amoeba Software, LLC
2: "set shufflable" and "set bookmarkable" lines added on 20070725
3: "add to Radio shows" line added on 20080904
4: song list processing added on 20090109 *)
5:
6: on process(theArgs)
7:
8: --Get the list of songs from the BBC Radio 2 page
9: set bbcurl to "http://www.bbc.co.uk/radio2/shows/lamarr/musicthis.shtml"
10: set cmd to "curl -s " & bbcurl & " | ~/bin/lamarr-song-list-text"
11: try
12: set songlist to do shell script cmd
13: on error
14: set songlist to "Couldn't retrieve song list from" & return & bbcurl
15: end try
16:
17: --Coerce args to be a list
18: if class of theArgs is not list then
19: set theArgs to {theArgs}
20: end if
21:
22: --Into iTunes ye files shall go
23: tell application "iTunes"
24: set theFile to item 1 of theArgs
25: set aTrack to (add theFile)
26: delay 60
27: set bookmarkable of aTrack to true
28: set shufflable of aTrack to false
29:
30: add (get location of aTrack) to playlist "Radio shows"
31: set lyrics of aTrack to songlist
32:
33: end tell
34:
35: end process
Lines 8–15 grab the HTML via curl and filter it through the Python script, which I’ve given the unfortunate name lamarr-song-list-text and saved in my ~/bin/ directory. The shell command that actually runs the retrieval and filtering operations is enclosed in a try block with the hope that any failures will be graceful. Line 31 then puts the songlist into the track’s lyrics field.
One thing that may seem weird to you is the 60 second delay in Line 26. It seems weird to me, too. As I was testing the script without the delay, I found that it sometimes worked and sometimes didn’t. I noticed that iTunes often spent time “processing” the track—whatever that entails—after it was imported, but the script didn’t wait at Line 25 for that processing to finish. When the script failed, the commands after Line 25 didn’t do their jobs. So I added the delay, thinking that might give iTunes enough processing time to finish the import before moving on to the other commands. The script has worked consistently since the delay was added.
Here’s what the results look like on my iPhone.
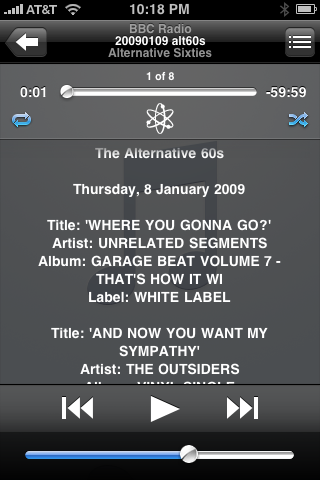
I assume the lines are centered to make lyrics look more like poetry to people who don’t read much poetry.
Most of the programs I post in this blog are idiosyncratic, but the two in this post are especially so. Unless you use AudioHijack Pro to record the BBC Radio 2 streams of Mark Lamarr’s shows, you will not be able to use these scripts directly. (They can be used with Lamarr’s “God’s Jukebox” show in addition to the Thursday night show by changing the URL for the song list page, but that doesn’t go very far in broadening their applicability.) But the ideas in the scripts can be used by anyone who records audio streams and would like to add textual information to the tracks.