
Library loan tracking again
March 9, 2009 at 10:26 PM by Dr. Drang
The webmaster of my local library is determined to drive me crazy. Last month, I wrote a script that
- logged into the library web site using all my family’s library card numbers,
- gathered the information on all the items we had on loan,
- formatted it into a nice HTML table, and
- emailed my wife and me the results.
The script ran every morning and was really useful, because it put all the information in one spot and let us consolidate our trips to the library. No more “Oh, I should have returned that book, too; I didn’t know it was due in a few days.”
Here’s what the daily email looked like on my iPhone:
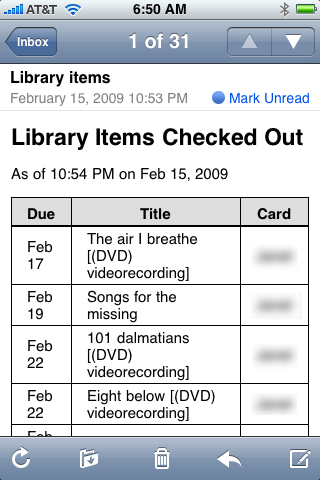
About a week after I’d debugged the script and started running it regularly, it failed because the library changed its login page. OK, that’s life in the screen-scraping world. I decided to dig into the code that evening and change it to the new login page. By the time I got started, the login page had changed again, back almost to the same state it had been the day before.
That seemed weird, but I made the few changes necessary to get the login working again and also cleaned up a new chunk of code I’d been working on to include the items we’d put holds on. I described the expanded script in a post at the end of February. Here’s what the new holds section of the email looked like on my iPhone:
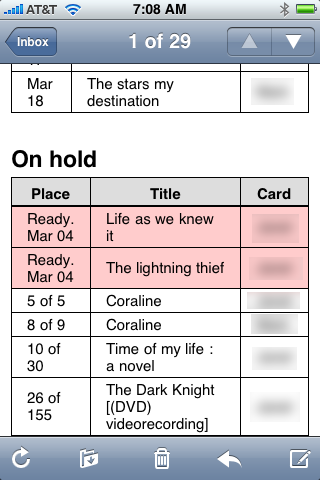
The pink background for the items ready to be picked up is also used for items that are due (or overdue).
Several days ago, the library changed again, and this the changes were significant and didn’t disappear after a day or two. I emailed a politely-worded WTF message to the webmaster and asked if the login page was going to settle down. (I also took the opportunity to complain about a few broken links on the login page as well as some poor formatting due to a typo in one of the HTML tags—all of which were promptly fixed.) The webmaster apologized for the back and forth and gave the impression—but didn’t say outright—that the new login page is here to stay.
So rewrote the checkcards.py script again. This time, I used the Python mechanize library the way it was meant to be used, as a way of creating automated browser sessions. The earlier versions of the script used it simply as a cookie handler. An added benefit of this change is that it should still work even if the library goes back to its earlier login page. Here’s the code:
1: #!/usr/bin/python
2:
3: import mechanize
4: from BeautifulSoup import BeautifulSoup
5: from time import strptime, strftime, localtime
6: import re
7:
8: # Card and email information.
9: mailFrom = 'dad@example.com'
10: mailTo = 'dad@example.com, mom@example.com'
11: cardList = [
12: {'patron' : 'Dad', 'code' : '123456789012', 'pin' : '12345'},
13: {'patron' : 'Mom', 'code' : '456789012345', 'pin' : '67890'},
14: {'patron' : 'Kid', 'code' : '789012345678', 'pin' : '34567'}]
15:
16: # The URLs for the library's account information.
17: # Login
18: lURL = 'https://encore.naperville-lib.org:443/iii/cas/login?service=http%3A%2F%2Fdatabase.naperville-lib.org%3A8113%2Fiii%2Fmfrpro-naper%2Fj_acegi_cas_security_check'
19: # Checked-out items
20: cURL = 'https://library.naperville-lib.org:443/patroninfo~S1/1110947/items'
21: # On-hold items
22: hURL = 'https://library.naperville-lib.org:443/patroninfo~S1/1110947/holds'
23:
24: # Initialize the lists of checked-out and on-hold items.
25: checkedOut = []
26: onHold = []
27:
28: # Function that returns an HTML table row for checked out items.
29: def cRow(data):
30: if data[0][0:3] <= localtime()[0:3]: # due today or earlier
31: classString = ' class="due"'
32: else:
33: classString = ''
34: return '''<tr%s><td>%s</td><td>%s</td><td>%s</td></tr>''' % \
35: (classString, strftime('%b %d', data[0]), data[2], data[1])
36:
37: # Function that returns an HTML table row for items on hold.
38: def hRow(data):
39: if data[0] <= 0: # Waiting for pickup or in transit
40: classString = ' class="due"'
41: else:
42: classString = ''
43: return '''<tr%s><td>%s</td><td>%s</td><td>%s</td></tr>''' % \
44: (classString, data[3], data[2], data[1])
45:
46: # Go through each card, collecting the lists of items.
47: for card in cardList:
48: # Need to use cookies to retain the session after login.
49: cookies = mechanize.CookieJar()
50: opener = mechanize.build_opener(mechanize.HTTPCookieProcessor(cookies))
51: mechanize.install_opener(opener)
52:
53: # Login
54: br = mechanize.Browser()
55: br.set_handle_robots(False)
56: br.open(lURL)
57: br.select_form(nr=0) # the login form is the first on the page
58: br['code'] = card['code']
59: br['pin'] = card['pin']
60: resp = br.submit()
61:
62: # Get the pages.
63: cHtml = br.open(cURL).read()
64: hHtml = br.open(hURL).read()
65:
66: # Parse the HTML.
67: cSoup = BeautifulSoup(cHtml)
68: hSoup = BeautifulSoup(hHtml)
69:
70: # Collect the table rows that contain the items.
71: loans = cSoup.findAll('tr', {'class' : 'patFuncEntry'})
72: holds = hSoup.findAll('tr', {'class' : 'patFuncEntry'})
73:
74: # Due dates and pickup dates are of the form mm-dd-yy.
75: dueDate = re.compile(r'\d\d-\d\d-\d\d')
76:
77: # Go through each row of checked out items, keeping only the title and due date.
78: for item in loans:
79: # The title is everything before the spaced slash in the patFuncTitle cell.
80: title = item.find('td', {'class' : 'patFuncTitle'}).a.string.split(' / ')[0].strip()
81: # The due date is somewhere in the patFuncStatus cell.
82: dueString = dueDate.findall(item.find('td', {'class' : 'patFuncStatus'}).contents[0])[0]
83: due = strptime(dueString, '%m-%d-%y')
84: # Add the item to the checked out list. Arrange tuple so items
85: # get sorted by due date.
86: checkedOut.append((due, card['patron'], title))
87:
88: # Go through each row of holds, keeping only the title and place in line.
89: for item in holds:
90: # Again, the title is everything before the spaced slash.
91: title = item.find('td', {'class' : 'patFuncTitle'}).a.string.split(' / ')[0].strip()
92: # The book's status in the hold queue will be either:
93: # 1. 'n of m holds'
94: # 2. 'Ready. Must be picked up by mm-dd-yy'
95: # 3. 'IN TRANSIT'
96: status = item.find('td', {'class' : 'patFuncStatus'}).contents[0].strip()
97: n = status.split()[0]
98: if n.isdigit(): # possibility 1
99: n = int(n)
100: status = status.replace(' holds', '')
101: elif n[:5] == 'Ready': # possibility 2
102: n = -1
103: dueString = dueDate.findall(status)[0]
104: status = 'Ready<br/> ' + strftime('%b %d', strptime(dueString, '%m-%d-%y'))
105: else: # possibility 3
106: n = 0
107: # Add the item to the on hold list. Arrange tuple so items
108: # get sorted by position in queue. The position is faked for
109: # items ready for pickup and in transit within the library.
110: onHold.append((n, card['patron'], title, status))
111:
112: # Sort the lists.
113: checkedOut.sort()
114: onHold.sort()
115:
116: # Templates for the email.
117: mailHeader = '''From: %s
118: To: %s
119: Subject: Library items
120: Content-Type: text/html
121: '''
122:
123: pageHeader = '''<html>
124: <head>
125: <style type="text/css">
126: body {
127: font-family: Helvetica, Sans-serif;
128: }
129: h1 {
130: font-size: 150%%;
131: margin-top: 1.5em;
132: margin-bottom: .25em;
133: }
134: table {
135: border-collapse: collapse;
136: }
137: table th {
138: padding: .5em 1em .25em 1em;
139: background-color: #ddd;
140: border: 1px solid black;
141: border-bottom: 2px solid black;
142: }
143: table tr.due {
144: background-color: #fcc;
145: }
146: table td {
147: padding: .25em 1em .25em 1em;
148: border: 1px solid black;
149: }
150: </style>
151: </head>
152: <body>
153: <p>As of %s</p>
154: '''
155:
156: tableTemplate = '''<h1>%s</h1>
157: <table>
158: <tr><th>%s</th><th>Title</th><th>Card</th></tr>
159: %s
160: </table>
161: '''
162:
163: pageFooter = '''</body>
164: </html>'''
165:
166: # Print out the email header and contents. This should be piped to sendmail.
167: print mailHeader % (mailFrom, mailTo)
168: print pageHeader % strftime('%I:%M %p on %b %d, %Y')
169: print (tableTemplate % ('Checked out', 'Due', '\n'.join([cRow(x) for x in checkedOut]))).encode('utf8')
170: print (tableTemplate % ('On hold', 'Status', '\n'.join([hRow(x) for x in onHold]))).encode('utf8')
171: print pageFooter
The primary changes from last time are the addition of Lines 53–60. This section of the code sets up a “browser” that enters the library card number and pin into the appropriate form fields and clicks the Submit button. From that point on, the script parses the loan and hold information via BeautifulSoup and sorts and formats it as before. My first post on this script explains in detail how the output is piped to sendmail and how I get it to run automatically every morning.
As I said in my first post about this script, the only people who can use this script directly are those who use my library. But the general outline of the script should be useful to anyone who wants to make his own library tracker.
Update 3/16/09
I added the encode('utf8') parts to Lines 169 and 170 to handle accented characters in the data from the library. I didn’t bother to encode the other printed strings because I’m in control of their contents and they don’t have any characters outside the ASCII range. Presumably, Python 3 will take care of such encoding automatically.